YARN: The Hadoop Batch System¶
YARN is the batch system in a Hadoop ecosystem, playing the same role as SLURM in the FT supercomputer.
To launch an application usually you just use the corresponing tool commands instead of using directly YARN commands.
For example to submit a Spark job you will use:
spark-submit
or in the case of Hive or Impala they take care of launching the MapReduce jobs needed to perform your SQL query automatically.
In case of MapReduce jobs you will launch them using the YARN CLI with a command similar to the following:
yarn jar application.jar DriverClass input output
It is also useful to list the running applications with:
yarn application -list
And, sometimes it is even easier to can check the overal status of the platform running:
yarn top
YARN takes care of collecting all the logs generated by your application in all the nodes, to see them you just have to run:
yarn logs -applicationId applicationId
And finally to kill an application you will use:
yarn application -kill applicationId
You can also find useful the YARN Web UI that allows to easily track the progress of your application and to get all the details about your job. You can access it through the HUE: A nice graphical interface to Hadoop.
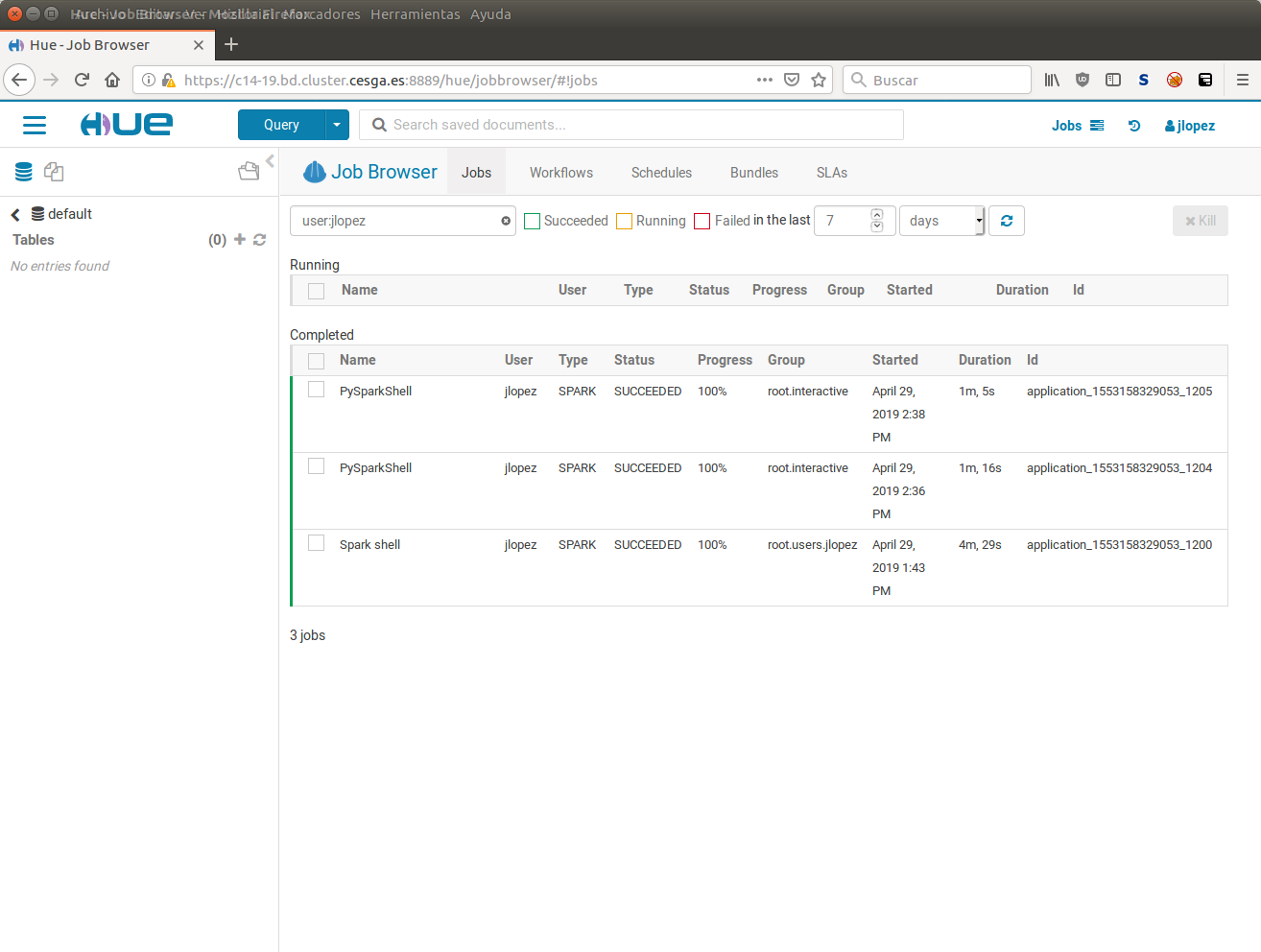
Monitoring jobs using HUE.
Note
We recommend to use HUE to access the tracking URL of your jobs. If you try to do it directly through the YARN UI you will find restrictions due to the fact that the YARN UI runs as the dr.who user.
By default jobs will be submitted to your own queue and resources will be shared with the rest of users using the YARN fair share scheduler and Dominant Resource Fairness (ie. it will take into account both CPU and memory).
Interactive jobs like Jupyter Notebooks run in a dedicate queue for interactive jobs.
There is also a queue that can be used for small but urgent jobs (urgent queue).
Jobs should be composed of lots of short running tasks so they share resources nicely with other jobs. In case of jobs with long running tasks that monopolize resources during large times the schedule is configured to preempt this tasks so they allow other applications to also run.
The common pattern in MapReduce jobs is to automatically split the job in lots of small tasks, and each of them runs in a small portion of the data. YARN is optimized for this type of jobs, for jobs that do not follow this pattern other platforms like the FT supercomputer with the SLURM batch system SLURM are usually best suited to the task.
In case of doubts or if you have special needs don’t hesitate to contact us.
For further information on how to use YARN you can check the YARN Tutorial that we have prepared to get you started and the Hadoop Documentation as reference.