Leverage the power of the new Big Data Infrastructure.
No need to learn how to deploy complex services, just connect and start using them.
Access a fully optimized infrastructure for Big Data applications.
Bring your data through a fast network interconnection or physically.
The service is free for Galician Universities and CSIC users the same way the HPC service is.
Just a quick overview of some of the available services ready-to-use.
Java-based file system that provides scalable and reliable data storage, and it was designed to span large clusters of commodity servers.
Allows multiple data processing engines such as interactive SQL, real-time streaming, data science and batch processing to handle data stored in a single platform, unlocking an entirely new approach to analytics.
Software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner.
Fast and general engine for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing.
Data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.
A tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
A web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text.
Web-based notebook that enables interactive data analytics. You can make beautiful data-driven, interactive and collaborative documents with SQL, Scala and more.
Web interface for analyzing data with Apache Hadoop. Hue applications let you browse HDFS, manage a Hive metastore, and run Hive and Cloudera Impala queries, HBase and Sqoop commands, Pig scripts, MapReduce jobs, and Oozie workflows.
Hadoop database, a distributed, scalable, big data store.
Workflow scheduler system to manage Apache Hadoop jobs.
A platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs.
A distributed real-time computation system for processing large volumes of high-velocity data.
A unified, high-throughput, low-latency platform for handling real-time data feeds.
A distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
An extensible framework for building high performance batch and interactive data processing applications, coordinated by YARN in Apache Hadoop.
A centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
Environment for quickly creating scalable performant machine learning applications.
An application to deploy existing distributed applications on an Apache Hadoop YARN cluster, monitor them and make them larger or smaller as desired even while the application is running..
A framework to simplify data pipeline processing and management on Hadoop clusters.
Scalable and extensible set of core foundational governance services enabling enterprises to effectively and efficiently meet their compliance requirements within Hadoop and allows integration with the whole enterprise data ecosystem.
A cluster manager that simplifies running applications on a scalable cluster of servers, and the heart of the Mesosphere system.
A container orchestration platform for Mesos and DCOS.
A tool for discovering and configuring services in our Big Data infrastructure.
A distributed database for managing large amounts of structured data across many commodity servers, while providing highly available service and no single point of failure.
A document-oriented database very easy to use.
A popular SQL database. Because not everything has to be NoSQL.
A distributed-replicated file system.
A job scheduler for Linux and Unix-like kernels, used by many of the world's supercomputers and computer clusters.
An Apache Hadoop distribution by Cloudera.
How to connect to the service.
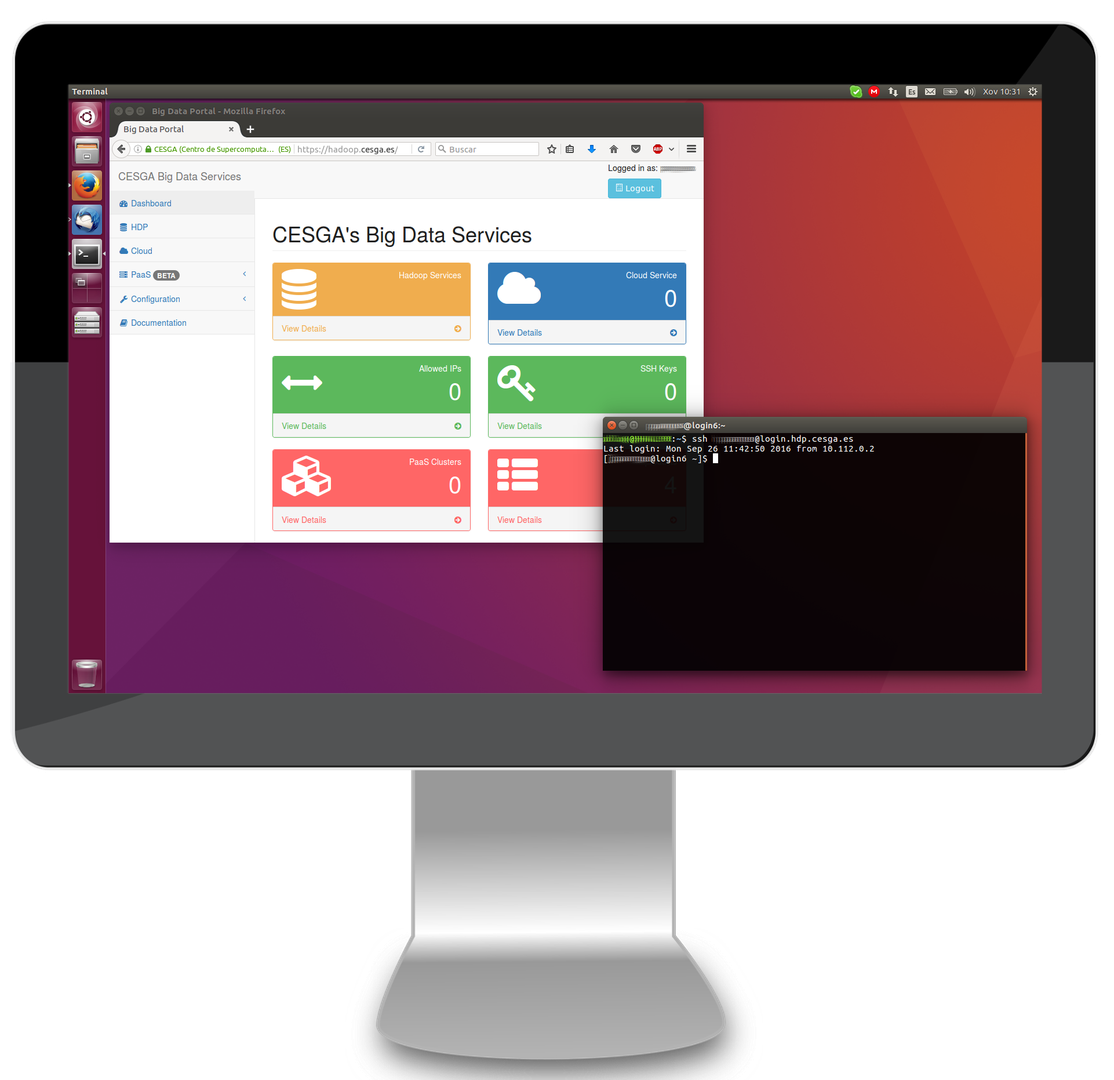
The services are only accessible once you are inside CESGA's VPN. Once you are inside the VPN you can connect using the WebUI or SSH depending on the service you will be using.
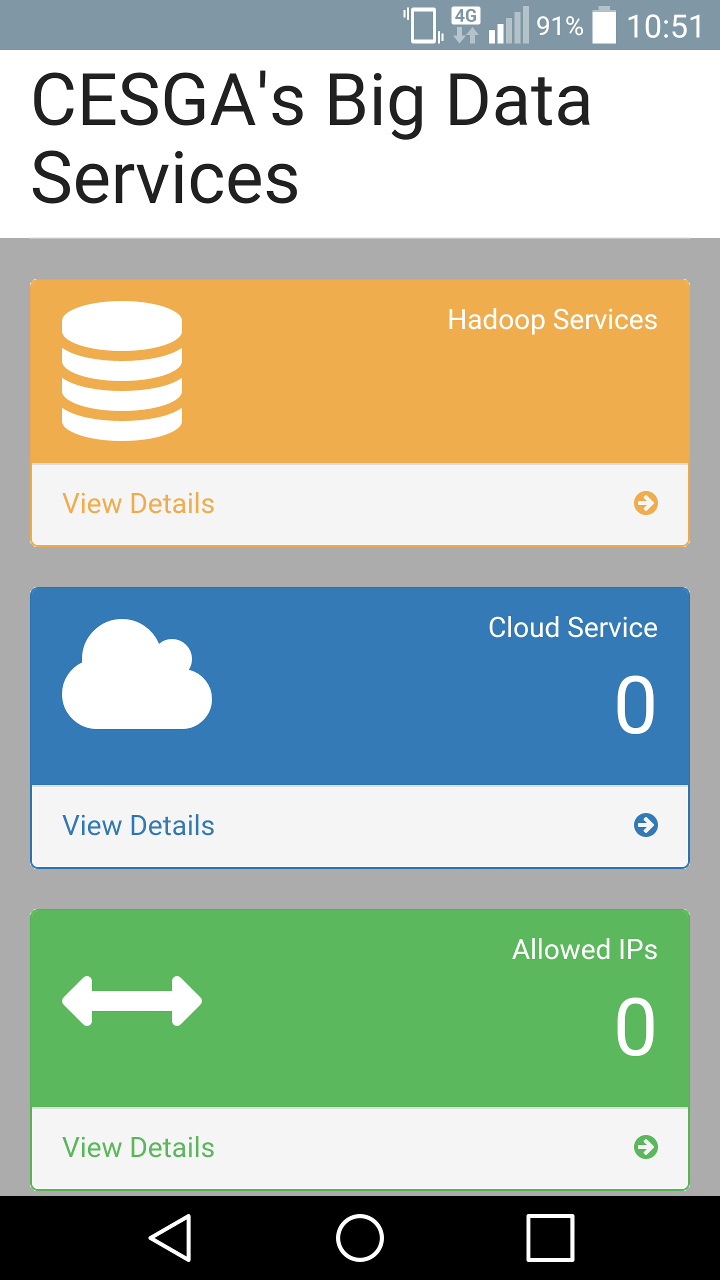
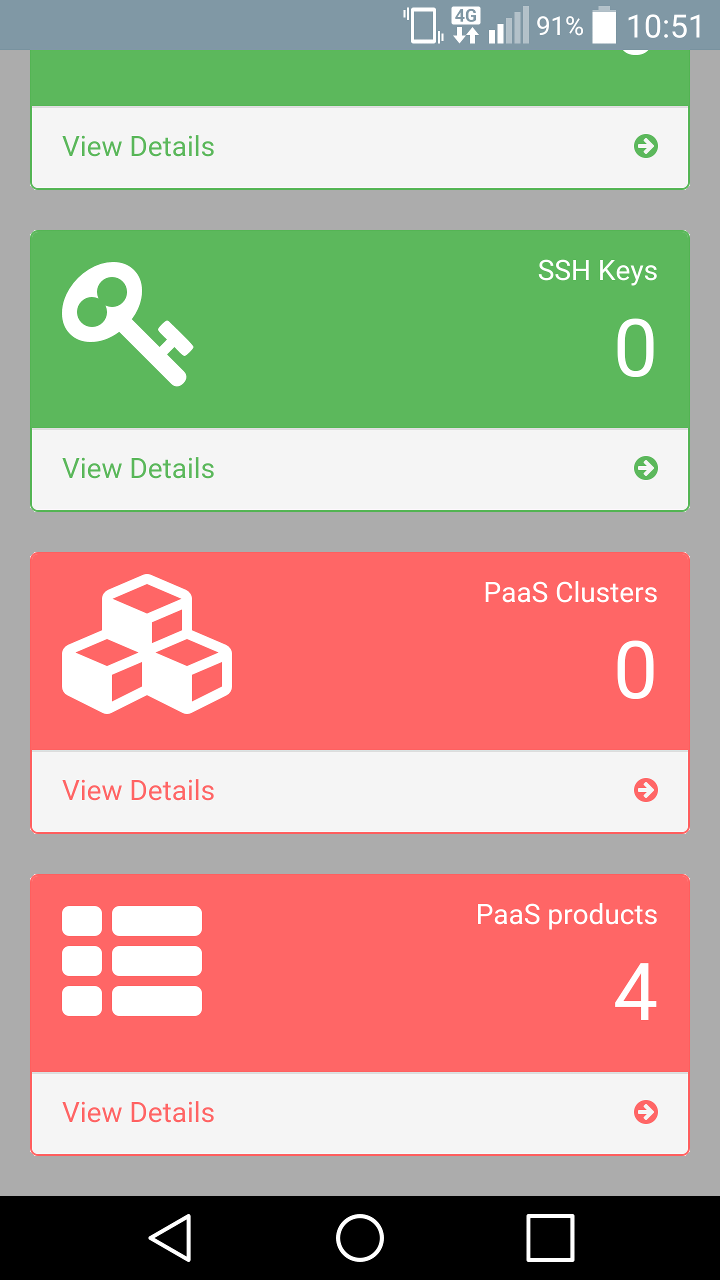



Your ready-to-use Hadoop ecosystem.
Based on Cloudera CDH 6.1.1.
Includes most of the components in the Hadoop ecosystem.
Ready to run production jobs.
A fully optimized infrastructure for Big Data applications.
When you need something outside the Hadoop ecosystem.
Enables you to deploy custom Big Data clusters.
Advanced disk-aware resource planning.
No virtualization overheads.
Includes a catalog of products ready to use: Cassandra, MongoDB, PostgreSQL.
We have prepared some tutorials to get you started using the platform.
We are here to help.
For any question contact  .
.